네이버 메일 EML 파일을 HTML로 변환하는 방법
네이버 메일이나 다른 이메일 플랫폼에서 EML 파일을 다운로드한 후, 이를 HTML 형식으로 변환하여 저장하는 방법은 다양한 활용 가능성을 제공합니다. 예를 들어, 이메일 내용을 웹 페이지로 저장하거나 PDF 파일로 공유할 때 유용합니다. 이번 글에서는 Python 코드를 사용하여 EML 파일을 HTML로 변환하고, HTML 파일을 PDF로 변환하는 방법을 알아보겠습니다.
필요한 도구와 환경
이 작업을 수행하기 위해 필요한 환경은 다음과 같습니다:
1. Python 설치: Python 공식 웹사이트에서 Python을 설치합니다.
2. 필수 라이브러리:
• pdfkit: HTML을 PDF로 변환하는 라이브러리.
• wkhtmltopdf: PDF 변환을 지원하는 도구로, 별도로 설치가 필요합니다.
전체소스코드
import os
from email import policy
from email.parser import BytesParser
import pdfkit
def eml_to_html(eml_file_path, output_html_path):
# EML 파일 열기
with open(eml_file_path, 'rb') as f:
msg = BytesParser(policy=policy.default).parse(f)
# HTML 콘텐츠 추출
html_content = None
for part in msg.walk():
if part.get_content_type() == 'text/html':
charset = part.get_content_charset() or 'utf-8' # 인코딩 감지, 없으면 UTF-8 사용
try:
html_content = part.get_payload(decode=True).decode(charset)
except (UnicodeDecodeError, LookupError):
print(f"인코딩 오류 발생, UTF-8로 시도합니다.")
html_content = part.get_payload(decode=True).decode('utf-8', errors='replace')
break
elif part.get_content_type() == 'text/plain' and html_content is None:
# HTML이 없는 경우, text/plain 사용
charset = part.get_content_charset() or 'utf-8'
try:
html_content = part.get_payload(decode=True).decode(charset)
except (UnicodeDecodeError, LookupError):
print(f"텍스트 인코딩 오류 발생, UTF-8로 시도합니다.")
html_content = part.get_payload(decode=True).decode('utf-8', errors='replace')
html_content = f"<pre>{html_content}</pre>"
if not html_content:
print("HTML 또는 텍스트 콘텐츠를 찾을 수 없습니다.")
return
# HTML 파일에 <meta charset="utf-8"> 삽입
if '<head>' in html_content:
html_content = html_content.replace('<head>', '<head>\n<meta charset="utf-8">', 1)
else:
html_content = '<meta charset="utf-8">\n' + html_content
# HTML 파일로 저장 (UTF-8 인코딩)
with open(output_html_path, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"변환 완료: {output_html_path}")
# HTML 파일을 PDF로 변환하는 함수
def convert_html_to_pdf(input_html: str, output_pdf: str):
try:
# 옵션 설정 (필요 시 wkhtmltopdf 경로 지정)
config = pdfkit.configuration(wkhtmltopdf="/usr/local/bin/wkhtmltopdf") # wkhtmltopdf 경로 설정
pdfkit.from_file(input_html, output_pdf, configuration=config)
print(f"PDF 파일이 성공적으로 생성되었습니다: {output_pdf}")
except Exception as e:
print(f"PDF 변환 중 오류 발생: {e}")
def main():
# 변환할 EML 파일 경로
eml_file = "koreaair.eml" # EML 파일 경로
output_html = "output.html" # 저장할 HTML 파일 경로
output_pdf_file = "example.pdf"
# 파일 존재 여부 확인
if not os.path.exists(eml_file):
print(f"파일을 찾을 수 없습니다: {eml_file}")
return
# 변환 실행
eml_to_html(eml_file, output_html)
convert_html_to_pdf(output_html, output_pdf_file)
if __name__ == "__main__":
main()
Python 코드 설명
아래 코드를 사용하여 EML 파일을 HTML로 변환하고, 필요 시 PDF로 변환할 수 있습니다.
1. EML 파일 열기
with open(eml_file_path, 'rb') as f:
msg = BytesParser(policy=policy.default).parse(f)• EML 파일을 바이너리 모드(rb)로 열어 BytesParser를 통해 메시지를 분석합니다.
2. HTML 콘텐츠 추출
for part in msg.walk():
if part.get_content_type() == 'text/html':
charset = part.get_content_charset() or 'utf-8'
html_content = part.get_payload(decode=True).decode(charset)• EML 파일은 여러 파트로 구성될 수 있습니다. msg.walk() 메서드를 통해 각각의 파트를 확인하며 text/html 콘텐츠를 찾습니다.
• 인코딩 정보를 감지하고, 디코딩을 통해 읽을 수 있는 HTML 콘텐츠로 변환합니다.
3. HTML 저장
with open(output_html_path, 'w', encoding='utf-8') as f:
f.write(html_content)• HTML 콘텐츠를 UTF-8로 인코딩하여 파일로 저장합니다.
4. HTML을 PDF로 변환
def main():
eml_file = "koreaair.eml"
output_html = "output.html"
output_pdf_file = "example.pdf"
if not os.path.exists(eml_file):
print(f"파일을 찾을 수 없습니다: {eml_file}")
return
eml_to_html(eml_file, output_html)
convert_html_to_pdf(output_html, output_pdf_file)• EML 파일 경로와 변환 후 저장할 HTML, PDF 파일 경로를 지정한 뒤 작업을 실행합니다.
주의사항
1. wkhtmltopdf 설치: 공식 다운로드 링크에서 설치하세요.
2. 파일 경로 설정: eml_file에 올바른 EML 파일 경로를 입력하세요.
3. 인코딩 문제 해결: 인코딩 오류가 발생하면 코드에서 기본 인코딩을 UTF-8로 설정했습니다.
시나리오
네이버에서 eml 파일을 다운로드 받는다

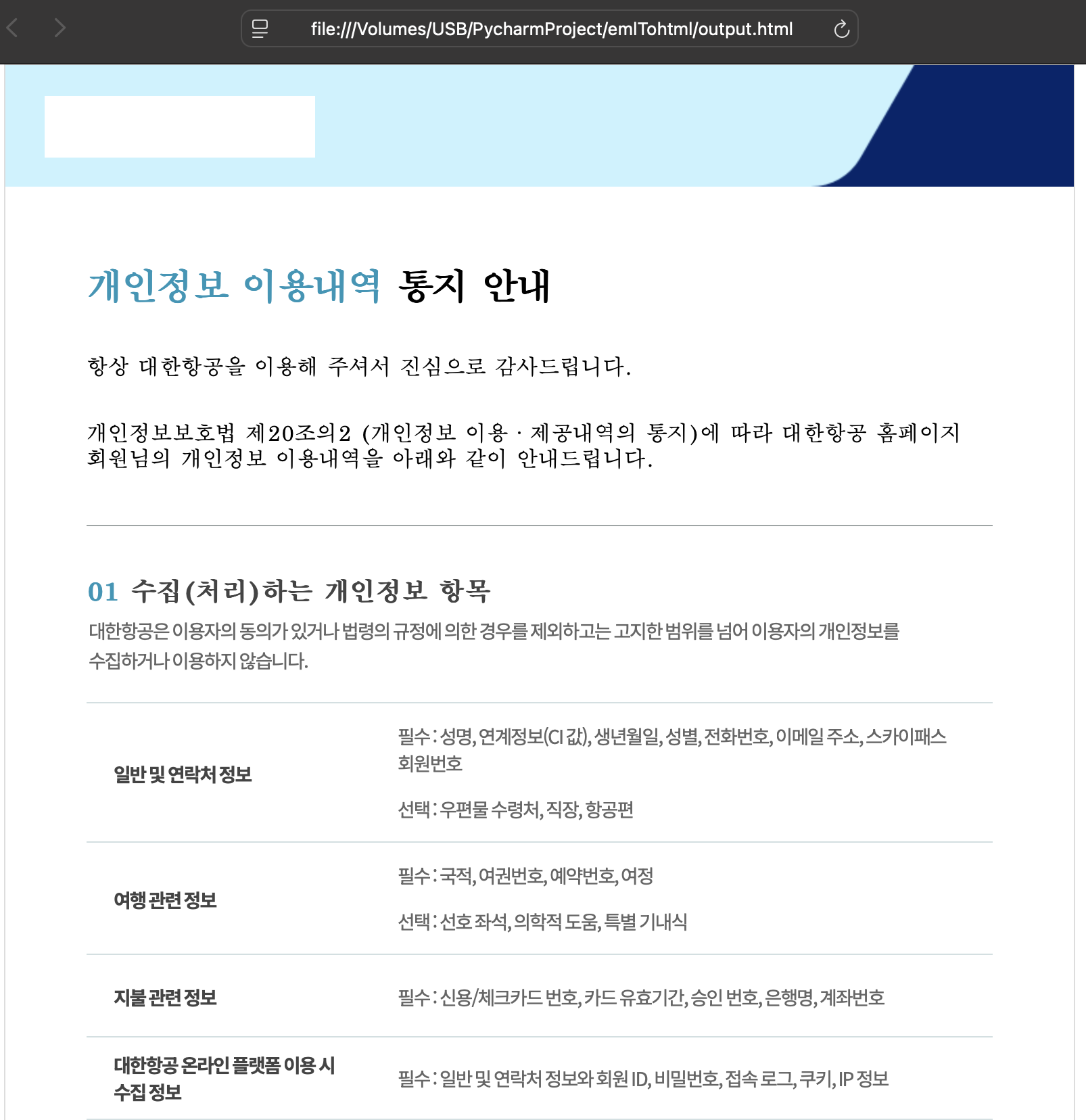
다운로드된 파일을 이름을 koreaair.eml 로 바꾸고 프로그램을 실행한다.

변경된 html 파일 pdf 파일도 확인할 수 있다.
활용 사례
이메일 기록 보관 및 관리.
이메일 내용을 PDF로 변환해 문서화.
이메일 템플릿을 HTML로 변환해 분석.
지금 바로 Python 코드를 실행하여 이메일 데이터를 효율적으로 관리해 보세요! 😊
'프로그래밍 > 코딩 TIP' 카테고리의 다른 글
| Python으로 실시간 환율 정보 가져오기: 네이버 금융 활용법 (0) | 2022.03.04 |
|---|---|
| Firebase 대안? Pushy로 간편한 푸시 알림 만들기 (0) | 2022.02.12 |

